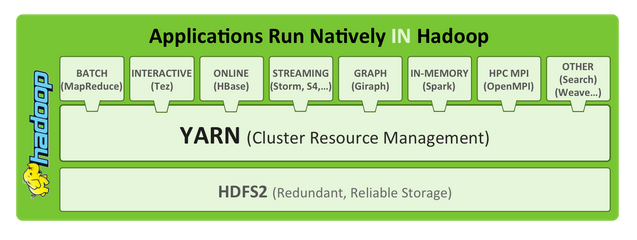
What is Hadoop?
Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project. It is licensed under the Apache License 2.0.
Why Hadoop?
Since there are a lot of low cost storage available, the key challenge for handling Big Data is how to read large amount of data fast. Hadoop is good for reading a big file in one shot. The default data block size (the smallest unit of data that a file system can store) of Hadoop is 64MB. The block size in disk is generally 4KB.
Hadoop today is not for: low latency data access , lots of small files ( each file will need metadata) , multiple writes, arbitrary file miseducation.
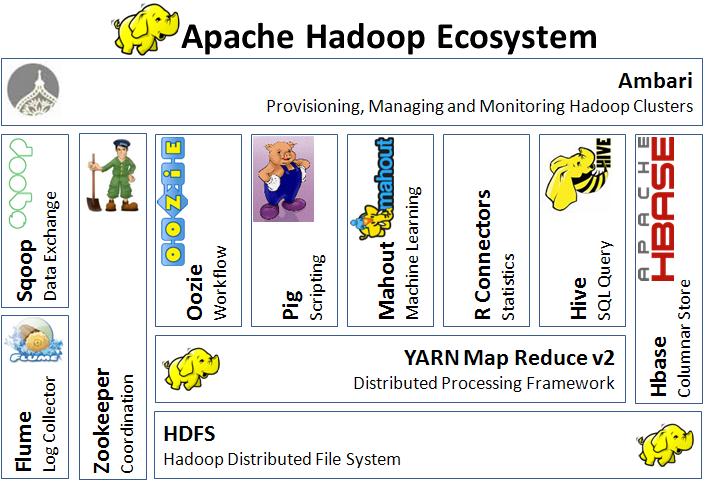
Hadoop Ecosystem
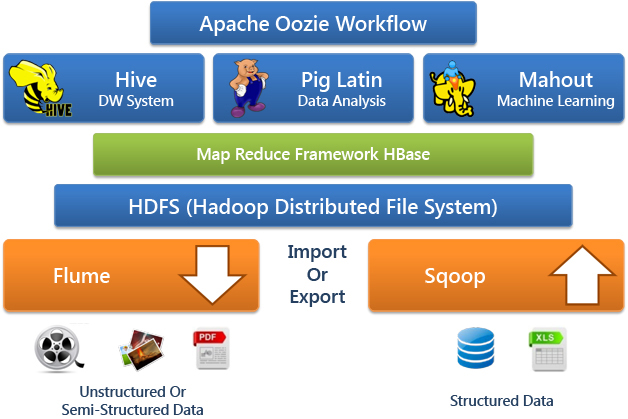
Flume – Import and Export Unstructured or Semi-Structured Data to/from Hadoop.
Sqoop (SQL+Hadoop) – Import and Export Structured Data to/from Hadoop.
HDFS – Hadoop distributed file system.
MapReduce – a programming model and associated implementation for processing and generating large data sets with a parallel, distributed algorithm on a cluster.
HBase – NoSQL Database, read/ write from HDFS to MapReduce, can be used for OLTP.
Pig – data analysis tool originally developed by yahoo, use procedural data-flow language (PigLatin), good for semi-structured data.
Hive – data warehouse tool, use SQL like language (HiveQL), good for structured data.
Mahout – a machine learning framework, used to develop social network/E- commerce recommendations.
Apache oozie – workflow scheduler and management tool, can schedule and run Hadoop jobs in parallel.
HDFS
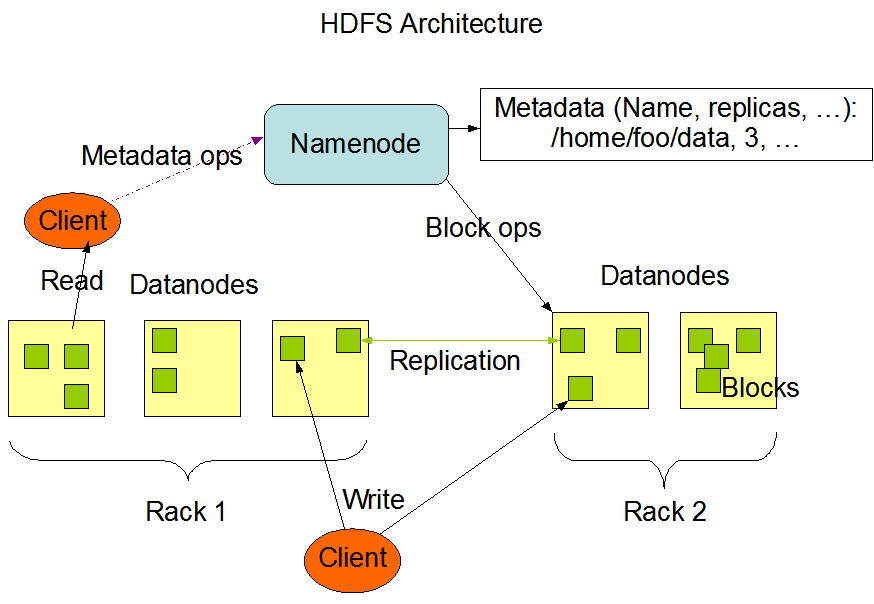
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode and a number of DataNodes.
NameNode is the master. It maintains and manages the blocks that are presented on DataNodes. It manages all the metadata of HDFS. NameNode only stores information in RAM. NameNode is associated with Job Tracker. There is a secondary NameNode in the system but it is not a hot standby of the NameNode. It reads from NameNode’s RAM and write to a file system ( hard disk) and used for disaster recovery.
DataNode is the slave. It serves the read/write requests from the clients. DataNode is associated with Task Tracker. A file is split into one or more blocks and these blocks are stored in a set of DataNodes.
The beauty of Hadoop is data localization. Traditional DFS is transferring TB of data in the network to process. Hadoop has the concept of data localization and only transfers KB level of code in the network. Data is processed locally in DataNodes.
MapReduce
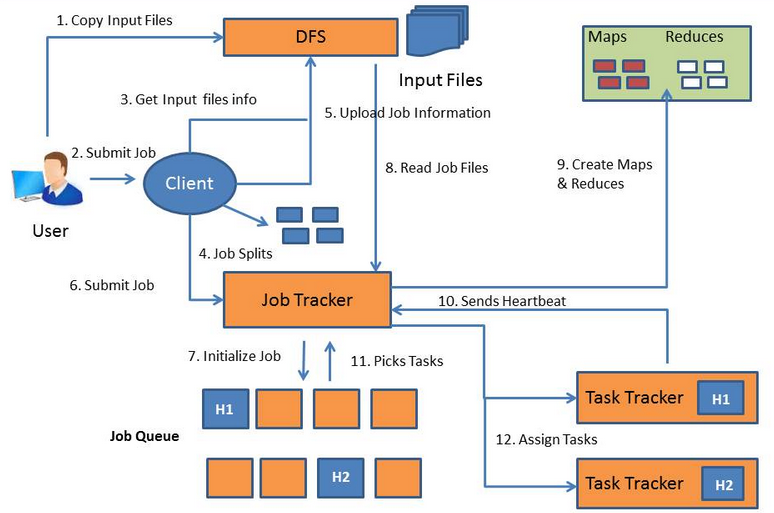
1. User (a person) copies the input file into the Distributed File System.
2. User submits the job to Client (software).
3. Client gets information about the input file.
4. Client split the job into multiple splits.
5. Client upload the job information to DFS.
6. Client submits job to Job Tracker.
7. Job Tracker initializes the job in job queue.
8. Job Tracker reads job files from DFS to understand the job.
9. Job Tracker creates Map tasks and Reduce Tasks based on the job type. The number of Map tasks equal the number of input splits, which is configurable. Each Map task is running on one input split. The output of the Map task will go to Reduce Task. The number of Reduce tasks generated can be defined. The Map and Reduce tasks are running on DataNodes.
10. Task Trackers send Heartbeats to Job Tracker to let it know they are available for tasks.
11. Job Tracker picks the Task Trackers that have the most local Data.
12. Job Tracker assign tasks to Task Trackers.
Once the tasks are completed, Task Tracker sends Heartbeat to Job Tracker agains and Job Tracker will assign more tasks.
Hadoop 1.0 vs 2.0

There are following challenges in Hadoop 1.0:
- Horizontal scalability of NameNode (bottleneck after 4000 nodes)
- NameNode is a single point of failure of the system
- Over burn of job tracker
- Cannot run non-MapReduce applications on HDFS
- No multi-tenancy: Ability to run multiple types of jobs on the same resource at the same time
How Hadoop 2.0 solve the challenges of Hadoop 1.0?
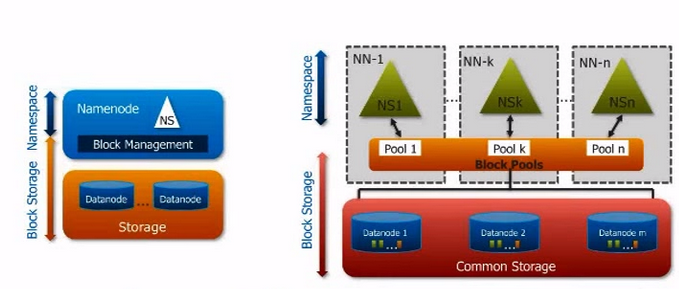
HDFS Federation – different NameNodes for different organizations. One Namespace has one NameNode. NameNodes are independent and do not talk to each other. Data is spread on large scale of DataNodes. All DataNodes are used as common storage for all NameNodes. Each DataNode is registered with all NameNodes. There is one block pool for one NameNode / Namespace but one DataNode can belong to multiple Namespaces.
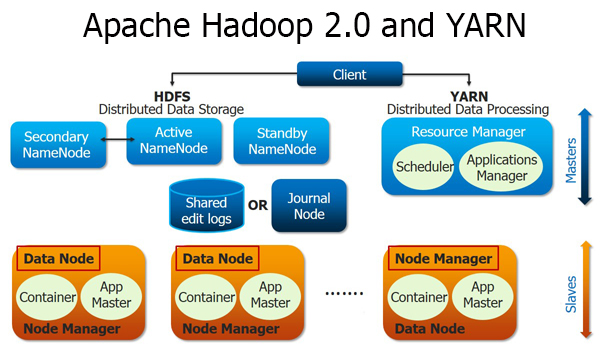
NameNode High Availability – One Namespace has one active NameNode, one stand by NameNode, and one secondary NameNode (optional).