

If you are relatively new to Machine Learning, you will probably have seen many technical terms that are some how confusing and difficult to understand.
To help myself and also other people to learn these terms, I decided to put together a list of 10 Machine Learning terms which are explained in simple English to make them easier to understand. So, if you’re struggling to understand the difference between Supervised vs Unsupervised Learning or classification vs clustering, you’ll enjoy this post.
Machine Learning
A subfield of computer science and artificial intelligence (AI) enables computers to act themselves instead of being explicitly programmed to do things. It focuses on designing systems that can learn, make decisions and predict based on data. Machine Learning programs are also designed to learn and improve over time when exposed to new data. Machine learning has been used for self-driving cars, web search, spam filtering and speech/graphic recognition systems. Machine Learning is often compared with Deep Learning and Pattern Recognition. If you want to learn more about the relationship of the three, this is a very good article.
Supervised Learning
A program that is “trained” on a pre-defined dataset. The training data has a set of training examples. Each example is a pair values of an input and a desired output. A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for calculating output based on input.The function will then be used by the algorithm to calculate output given input from new data, which does not have desired output available. Example: Using a training set of human tagged spam or non-spam emails to train a spam classifier algorithm. And then use the algorithm to classify if a new email without human tag is spam or not.
Unsupervised Learning
A program can automatically find patterns and relationships in an unlabeled dataset without being trained by a training dataset. Example: Analyzing a dataset of emails and automatically grouping related news by topic such as politics, sports with no prior knowledge or training. This is also known as the practice of clustering.
Classification
A sub-category of Supervised Learning, Classification is the process of taking input and assigning one of the categories to it, on the basis of a training set of data containing input whose category is known. Classification systems are usually used when predictions are of a discrete, or “yes or no” nature. Example: Mapping a picture of an animal to a cat or non-cat classification.
Regression
Another sub-category of supervised learning used when the predicted output differs to a discrete, or “yes or no” category as it falls into a continuous spectrum. Regression systems could be used to answer questions such as “How much?” or “How many?”. Example: Predicting the sales price of a house.
Decision Trees
A decision tree is a decision support tool that uses a tree-like graph or model of decisions and their possible consequences. Tree models where the target variable can take a finite set of values are called classification trees. tree models where the target variable can take continuous values are called regression trees.
Example of a classification tree:
Deep Learning
Deep learning refers to a category of machine learning algorithms that often use Artificial Neural Networks to generate models. Deep Learning algorithms are able to pick the best features themselves, while other Machine Learning algorithms normally have a set of predefined features to work with. Deep Learning, for example, have been very successful in solving Speech/Image Recognition problems due to their ability to pick the best features, as well as to express layers of representation. For example, when computer tries to recognize the pictures below, it will first break down the picture into different parts and pick the best features that it thinks will best recognize the parts. The it will compute the final output based on the results of all those parts.
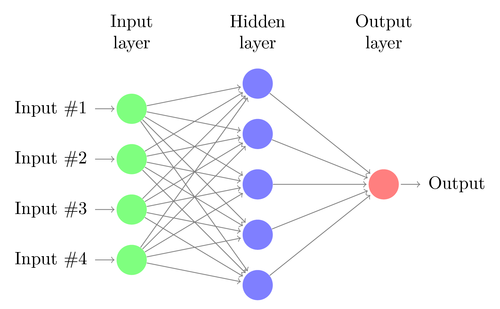
Neural Networks
Inspired by biological neural networks, artificial neural networks are a network of interconnected nodes that make up a model. They can be defined as statistical learning models that are used to estimate or approximate functions that depend on a large number of inputs and are generally unknown. For example, a neural network for handwriting recognition is defined by a set of input neurons which may be activated by the pixels of an input image. After being weighted and transformed by a function (determined by the network’s designer), the activations (pixels) of these neurons are then passed on to other neurons. This process is repeated until finally, an output neuron is activated. We can provide a set of training images with desired output to train the Neural network and the Neural network itself will figure out all the hidden layers. The we can use the Neural network to recognize new handwriting images. Neural networks are usually used when the volume of inputs is far too large for standard machine learning approaches previously discussed.
Generative Model
A Generative Model is a model used to generate data values when some parameters are hidden. Generative models are used in Machine Learning for either modeling data directly or as an intermediate step to forming a conditional probability density function. In other terms you model p(x,y) in order to make predictions (which can be converted to p(x|y) by applying the Bayes rule) as well as to be able to generate likely (x,y) pairs. For example, you have a friend named Tom, who lives far away from you. You has no information about if it rains where Tom lives. But you talked to Tom and he told you if he bought umbrella or not. The choice of whether Tom brings an umbrella is determined exclusively by the weather on a given day. Based on what Tom told you each day, you tries to guess if it rained where Tom lives. It is widely used in Unsupervised Learning. Examples of Generative Models include Naive Bayes, Latent Dirichlet allocation, Hidden Markov model and Gaussian mixture model.
Discriminative Model
Discriminative Models or conditional models, are a class of models used in Machine Learning to model the dependence of an unobserved variable y on an observed variable x. As these models try to calculate conditional probabilities (i.e. p(y|x) ), they are often used in Supervised Learning. Examples include Logistic regression, Support vector machines, Linear regression and Neural networks.